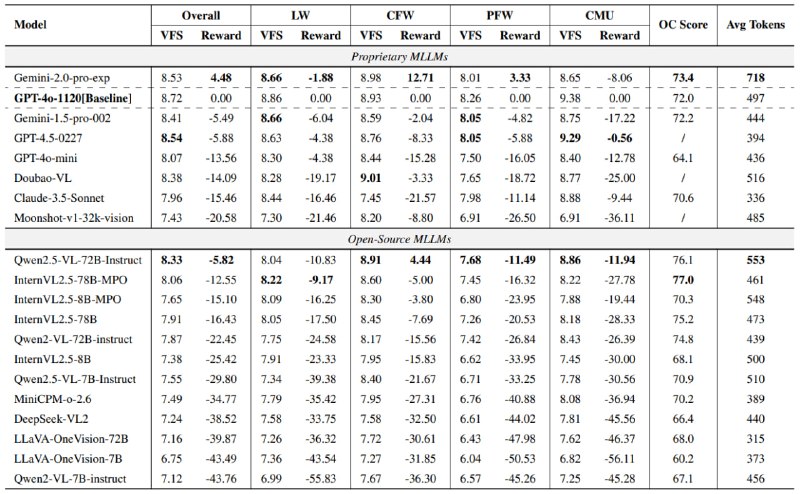
浙江大学与上海人工智能实验室等团队发布全球首个面向真实场景的多模态创造力评测基准Creation-MMBench,该基准覆盖文学创作、日常功能性写作、专业功能性写作及多模态理解与创作四大类51项任务,包含765个高难度测试案例,通过复杂情境和跨域图像(千张图片涉及30个类别)全面评估多模态大模型的视觉创意智能。实验结果显示,GPT-4.5在整体创造力表现上弱于GPT-4o和Gemini-2.0-Pro,而开源模型如Qwen2.5-VL虽接近闭源模型水平但仍存差距。基准采用双重评估体系(视觉事实性评分和创意奖励分),并揭示视觉指令微调可能对模型创造力产生负面影响。Creation-MMBench已集成至VLMEvalKit支持一键评测。
来源:IT之家 / arxiv