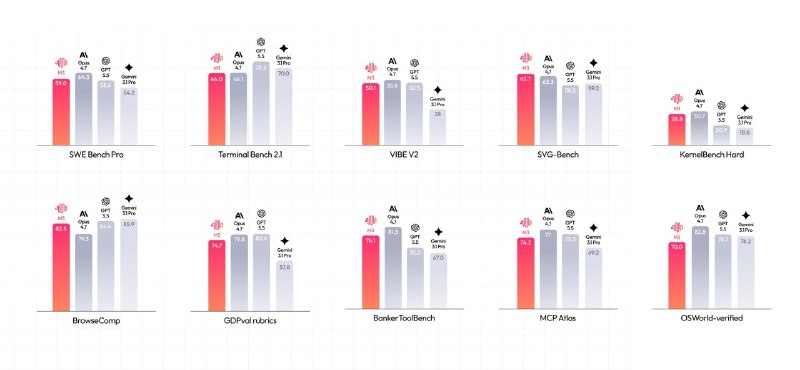
MiniMax 今日发布 M3 前沿模型,定位为面向 Coding、Agent 和多模态任务的统一模型。官方称,M3 采用 MiniMax Sparse Attention(MSA)稀疏注意力架构,最高支持 100 万 token 上下文,并原生支持图片、视频输入以及 Computer Use 桌面操作能力。
MSA 主要用于降低长上下文场景下的计算成本。MiniMax 称,在 100 万上下文下,M3 每 token 计算量为上代模型的 1/20,prefilling 阶段加速超过 9 倍,decoding 阶段加速超过 15 倍。
minimax 将在未来 10 天内将更新 M3 技术报告,并开源对应模型权重。
来源:MiniMax 官方博客