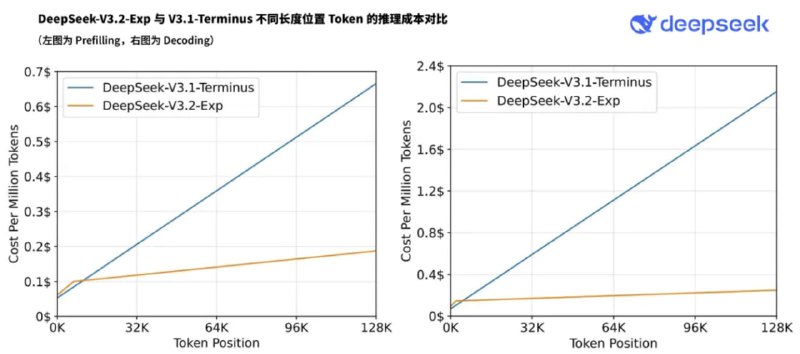
DeepSeek正式发布V3.2-Exp实验版模型,这是其下一代架构的中间步骤。该模型在V3.1-Terminus基础上引入了DeepSeek稀疏注意力(DSA)机制,旨在探索和验证长文本场景下的训练与推理效率优化。
DSA实现了细粒度稀疏注意力,在保持模型输出质量几乎不变的情况下,显著提升了长文本处理的计算效率。在多个公开基准测试中,V3.2-Exp展现了与V3.1-Terminus相当的性能表现,标志着DeepSeek在高效Transformer架构研究方面的新进展。
来源:HuggingFace